
I am a third-year PhD student in the MAP-Group at Tongji University, under the supervision of Prof. Lin Zhang and Prof. Ying Shen. I obtained my bachelor’s degree from Tongji University in 2023, after which I began my doctoral studies.
My research interests lie in the field of Embodied AI, focusing on enabling robots to perceive and interact with the physical world through advanced learning representations. Specifically, my work explores: Multimodal Representation for Robotics, Vision-Language Fields, and Generalist Robot Models.
My goal is to leverage multimodal perception and large-scale models to enhance the generalization and manipulation capabilities of robots in complex, real-world environments.
🔥 News
- 2026.03: 🎉 Invited to serve as a Reviewer for NeurIPS 2026.
- 2026.02: 🎉 Invited to serve as a Reviewer for ECCV 2026.
- 2026.02: 🎉 Our paper on Vision-Language Grounding and Grasping got accepted in CVPR 2026.
- 2025.11: 🎉 Our paper on Efficient Image Representation got accepted in AAAI 2026.
- 2024.12: 🎉 Our paper on Continuous Audio Signal Representation got accepted in AAAI 2025.
- 2024.12: 🎉 Our paper on Audio-Visual Navigation got accepted in AAAI 2025.
- 2024.07: 🎉 Our paper on 3D Semantic Gaussian Splatting Field got accepted in ACM MM 2024.
📝 Publications
Linfei Li, Lin Zhang, Ying Shen
[webpage] [code] [arXiv] [abstract] [bibtex] Visual-language grounding aims to establish semantic correspondences between natural language and visual entities, enabling models to accurately identify and localize target objects based on textual instructions. Existing VLG approaches focus on coarse-grained, object-level localization, while traditional robotic grasping methods rely predominantly on geometric cues and lack language guidance, which limits their applicability in language-driven manipulation scenarios. To address these limitations, we propose the RealVLG framework, which integrates the RealVLG-11B dataset and the RealVLG-R1 model to unify real-world visual-language grounding and grasping tasks. RealVLG-11B dataset provides multi-granularity annotations including bounding boxes, segmentation masks, grasp poses, contact points, and human-verified fine-grained language descriptions, covering approximately 165,000 images, over 800 object instances, 1.3 million segmentation, detection, and language annotations, and roughly 11 billion grasping examples. Building on this dataset, RealVLG-R1 employs Reinforcement Fine-tuning on pretrained large-scale vision-language models to predict bounding boxes, segmentation masks, grasp poses, and contact points in a unified manner given natural language instructions. Experimental results demonstrate that RealVLG supports zero-shot perception and manipulation in real-world unseen environments, establishing a unified semantic-visual multimodal benchmark that provides a comprehensive data and evaluation platform for language-driven robotic perception and grasping policy learning. @article{li2026realvlg, title={RealVLG-R1: A Large-Scale Real-World Visual-Language Grounding Benchmark for Robotic Perception and Manipulation}, author={Li, Linfei and Zhang, Lin and Shen, Ying}, journal={arXiv preprint arXiv:2603.14880}, year={2026} }

Linfei Li, Fengyi Zhang, Zhong Wang, Lin Zhang, Ying Shen
[code] [arXiv] [abstract] [bibtex] Implicit Neural Representations (INRs) have gained success in various signal processing tasks due to their advantages of continuity and infinite resolution. However, the factors influencing their effectiveness and limitations remain underexplored. To better understand these factors, we leverage insights from Neural Tangent Kernel (NTK) theory to analyze how model architectures (classic MLP and emerging KAN), positional encoding, and nonlinear primitives affect the response to signals of varying frequencies. Building on this analysis, we introduce INR-Bench, the first comprehensive benchmark specifically designed for multimodal INR tasks. It includes 56 variants of Coordinate-MLP models (featuring 4 types of positional encoding and 14 activation functions) and 22 Coordinate-KAN models with distinct basis functions, evaluated across 9 implicit multimodal tasks. These tasks cover both forward and inverse problems, offering a robust platform to highlight the strengths and limitations of different neural models, thereby establishing a solid foundation for future research. @article{li2025inr, title={INR-Bench: A Unified Benchmark for Implicit Neural Representations in Multi-Domain Regression and Reconstruction}, author={Li, Linfei and Zhang, Fengyi and Wang, Zhong and Zhang, Lin and Shen, Ying}, journal={arXiv preprint arXiv:2510.10188}, year={2025} }

SmartSplat: Feature-Smart Gaussians for Scalable Compression of Ultra-High-Resolution Images
Linfei Li, Lin Zhang, Zhong Wang, Ying Shen
[webpage] [code] [arXiv] [abstract] [bibtex] Recent advances in generative AI have accelerated the production of ultra-high-resolution visual content. However, traditional image formats face significant limitations in efficient compression and real-time decoding, which restricts their applicability on end-user devices. Inspired by 3D Gaussian Splatting, 2D Gaussian image models have achieved notable progress in enhancing image representation efficiency and quality. Nevertheless, existing methods struggle to balance compression ratios and reconstruction fidelity in ultra-high-resolution scenarios. To address these challenges, we propose SmartSplat, a highly adaptive and feature-aware GS-based image compression framework that effectively supports arbitrary image resolutions and compression ratios. By leveraging image-aware features such as gradients and color variances, SmartSplat introduces a Gradient-Color Guided Variational Sampling strategy alongside an Exclusion-based Uniform Sampling scheme, significantly improving the non-overlapping coverage of Gaussian primitives in pixel space. Additionally, a Scale-Adaptive Gaussian Color Sampling method is proposed to enhance the initialization of Gaussian color attributes across scales. Through joint optimization of spatial layout, scale, and color initialization, SmartSplat can efficiently capture both local structures and global textures of images using a limited number of Gaussians, achieving superior reconstruction quality under high compression ratios. Extensive experiments on DIV8K and a newly created 16K dataset demonstrate that SmartSplat significantly outperforms state-of-the-art methods at comparable compression ratios and surpasses their compression limits, exhibiting strong scalability and practical applicability. This framework can effectively alleviate the storage and transmission burdens of ultra-high-resolution images, providing a robust foundation for future high-efficiency visual content processing. @article{Li2026smartsplat, title = {SmartSplat: Feature-Smart Gaussians for Scalable Compression of Ultra-High-Resolution Images}, volume = {40}, number = {8}, journal = {Proceedings of the AAAI Conference on Artificial Intelligence}, author = {Li, Linfei and Zhang, Lin and Wang, Zhong and Shen, Ying}, year = {2026}, pages = {6315-6323} }
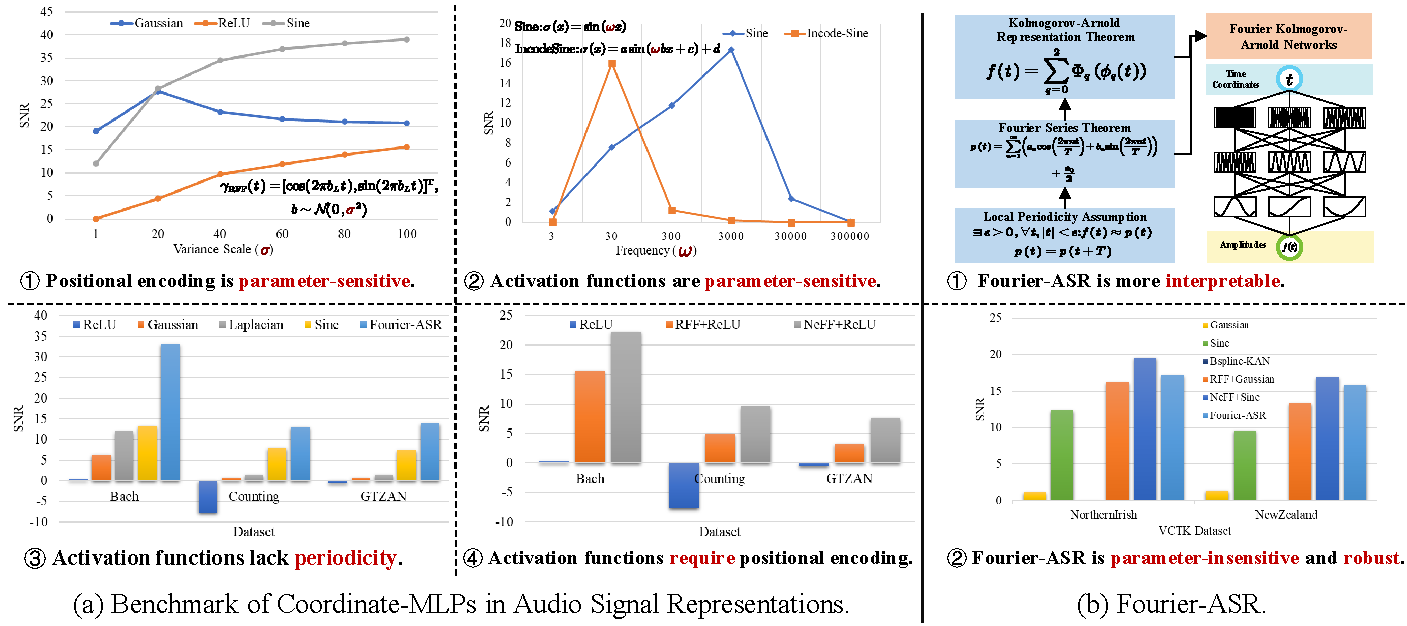
Linfei Li, Lin Zhang, Zhong Wang, Fengyi Zhang, Zelin Li, Ying Shen
[webpage] [code] [arXiv] [abstract] [bibtex] Although Coordinate-MLP-based implicit neural representations have excelled in representing radiance fields, 3D shapes, and images, their application to audio signals remains underexplored. To fill this gap, we investigate existing implicit neural representations, from which we extract 3 types of positional encoding and 16 commonly used activation functions. Through combinatorial design, we establish the first benchmark for Coordinate-MLPs in audio signal representations. Our benchmark reveals that Coordinate-MLPs require complex hyperparameter tuning and frequency-dependent initialization, limiting their robustness. To address these issues, we propose Fourier-ASR, a novel framework based on the Fourier series theorem and the Kolmogorov-Arnold representation theorem. Fourier-ASR introduces Fourier Kolmogorov-Arnold Networks (Fourier-KAN), which leverage periodicity and strong nonlinearity to represent audio signals, eliminating the need for additional positional encoding. Furthermore, a Frequency-adaptive Learning Strategy (FaLS) is proposed to enhance the convergence of Fourier-KAN by capturing high-frequency components and preventing overfitting of low-frequency signals. Extensive experiments conducted on natural speech and music datasets reveal that: (1) well-designed positional encoding and activation functions in Coordinate-MLPs can effectively improve audio representation quality; and (2) Fourier-ASR can robustly represent complex audio signals without extensive hyperparameter tuning. Looking ahead, the continuity and infinite resolution of implicit audio representations make our research highly promising for tasks such as audio compression, synthesis, and generation. @article{Li2025nerf, title={Representing Sounds as Neural Amplitude Fields: A Benchmark of Coordinate-MLPs and a Fourier Kolmogorov-Arnold Framework}, volume={39}, number={23}, journal={Proceedings of the AAAI Conference on Artificial Intelligence}, author={Li, Linfei and Zhang, Lin and Wang, Zhong and Zhang, Fengyi and Li, Zelin and Shen, Ying}, year={2025}, pages={24458–24466} }
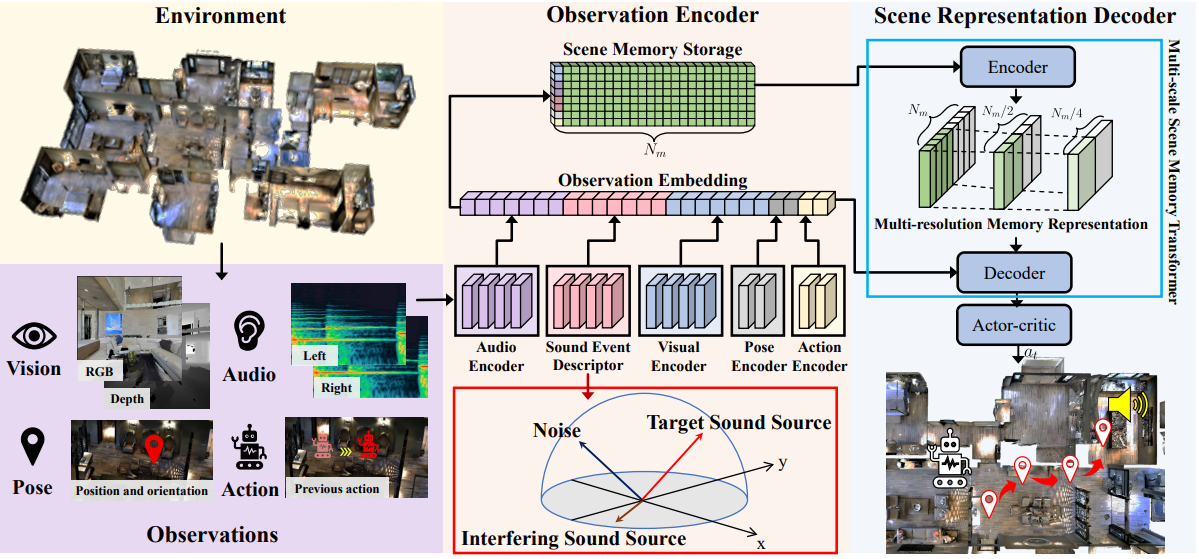
Zhanbo Shi, Lin Zhang, Linfei Li, Ying Shen
[code] [pdf] [appendix] [abstract] [bibtex] Audio-visual navigation has received considerable attention in recent years. However, the majority of related investigations have focused on single sound-source scenarios. Studies in this field for multiple sound-source scenarios remain underexplored due to the limitations of two aspects. First, the existing audio-visual navigation dataset only has limited audio samples, making it difficult to simulate diverse multiple sound-source environments. Second, existing navigation frameworks are mainly designed for single sound-source scenarios, thus their performance is severely reduced in multiple sound-source scenarios. In this work, we make an attempt to fill in these two research gaps to some extent. First, we establish a large-scale BEnchmark Dataset for Audio-Vsual Navigation, namely BeDAViN. This dataset consists of 2,258 audio samples with a total duration of 10.8 hours, which is more than 33 times longer than the existing audio dataset employed in the audio-visual navigation task. Second, we propose a new Embodied Navigation framework for MUltiple Sound-Sources Scenarios called ENMuS3. There are mainly two essential components in ENMuS3, the sound event descriptor and the multi-scale scene memory transformer. The former component equips the agent with the ability to extract spatial and semantic features of the target sound-source among multiple sound-sources, while the latter provides the ability to track the target object effectively in noisy environments. Experimental results on our BeDAViN show that ENMuS3 strongly outperforms its counterparts with a significant improvement in success rates across diverse scenarios. @article{Shi_Zhang_Li_Shen_2025, title = {Towards Audio-Visual Navigation in Noisy Environments: A Large-Scale Benchmark Dataset and an Architecture Considering Multiple Sound-Sources}, volume = {39}, number = {14}, journal = {Proceedings of the AAAI Conference on Artificial Intelligence}, author = {Shi, Zhanbo and Zhang, Lin and Li, Linfei and Shen, Ying}, year = {2025}, pages = {14673-14680} }
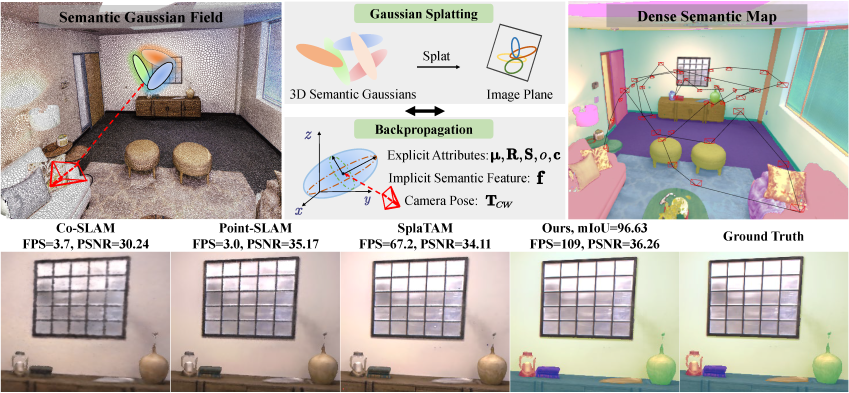
GS3LAM: Gaussian Semantic Splatting SLAM
Linfei Li, Lin Zhang, Zhong Wang, Ying Shen
[webpage] [code] [pdf] [abstract] [bibtex] Recently, the multi-modal fusion of RGB, depth, and semantics has shown great potential in the domain of dense Simultaneous Localization and Mapping (SLAM), as known as dense semantic SLAM. Yet a prerequisite for generating consistent and continuous semantic maps is the availability of dense, efficient, and scalable scene representations. To date, existing semantic SLAM systems based on explicit scene representations (points/meshes/surfels) are limited by their resolutions and inabilities to predict unknown areas, thus failing to generate dense maps. Contrarily, a few implicit scene representations (Neural Radiance Fields) to deal with these problems rely on time-consuming ray tracing-based volume rendering technique, which cannot meet the real-time rendering requirements of SLAM. Fortunately, the Gaussian Splatting scene representation has recently emerged, which inherits the efficiency and scalability of point/surfel representations while smoothly represents geometric structures in a continuous manner, showing promise in addressing the aforementioned challenges. To this end, we propose GS3LAM, a Gaussian Semantic Splatting SLAM framework, which takes multimodal data as input and can render consistent, continuous dense semantic maps in real-time. To fuse multimodal data, GS3LAM models the scene as a Semantic Gaussian Field (SG-Field), and jointly optimizes camera poses and the field by establishing error constraints between observed and predicted data. Furthermore, a Depth-adaptive Scale Regularization (DSR) scheme is proposed to tackle the problem of misalignment between scale-invariant Gaussians and geometric surfaces within the SG-Field. To mitigate the forgetting phenomenon, we propose an effective Random Sampling-based Keyframe Mapping (RSKM) strategy, which exhibits notable superiority over local covisibility optimization strategies commonly utilized in 3DGS-based SLAM systems. Extensive experiments conducted on the benchmark datasets reveal that compared with state-of-the-art competitors, GS3 LAM demonstrates increased tracking robustness, superior real-time rendering quality, and enhanced semantic reconstruction precision. @inproceedings{li2024gs3lam, author = {Li, Linfei and Zhang, Lin and Wang, Zhong and Shen, Ying}, title = {GS3LAM: Gaussian Semantic Splatting SLAM}, year = {2024}, booktitle = {Proceedings of the 32nd ACM International Conference on Multimedia}, pages = {3019–3027}, numpages = {9}, }
📖 Educations
- 2023.09 - 2029.03 (expected), PhD, Computer Science and Technology, Tongji University.
- 2019.09 - 2023.07, Undergraduate, Software Engineering, Tongji University.
🎖️ Honors and Awards
- 2025.12, Tongji University Outstanding Doctoral Student Scholarship
- 2025.11, Tongji University Outstanding Doctoral Student
- 2023.08, Outstanding Graduate of Tongji University
- 2023.07, Outstanding Undergraduate Thesis of Tongji University
📚 Academic Services
- Reviewer: CVPR 2026, ICML 2025, AAAI 2025/2026, MM 2025
🤝 Project Experience
- Changchun City Science and Technology Tackling and Open Competition Program “Development of In-Vehicle High-Precision Augmented Reality (AR) Navigation Software Based on Multi-Sensor Fusion Technology” (24JB), 2025.01–2025.12, Changchun Municipal Bureau of Science and Technology.